scikit-learnのサンプルデータセットを取り込み、確認のため5レコードを表示します。
# breast_cancer_wisconsin_data.csv を取り込む
import pandas as pd
bcw_data = pd.read_csv('breast_cancer_wisconsin_data.csv')
# 先頭の5行のみ表示する(
bcw_data.head()
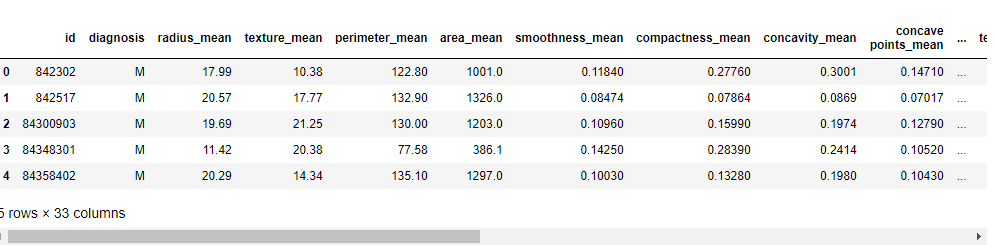
このデータには以下に示す項目以外に30項目程度の項目があります。
- id:連番
- diagnosis:”B”か”M”の文字が格納されている(”B”:良性、”M”:悪性)
- radius_mean:中心から外周までの平均距離(半径)
- texture_mean:グレースケール(色の濃さ)の平均値
- perimeter_mean:外周の平均の長さ
今回は radius_mean(半径)を説明変数、diagnosis(良性か悪性か)を目的変数として回帰を行います。
計測データ(X)と教師データ(y)に分ける
# X と y を作成する import numpy as np X = bcw_data.loc[:,"radius_mean"] y = bcw_data.loc[:,"diagnosis"] # DataFrame形式から ndarray 形式に変換 #X = np.array(X).reshape(-1,1) #y = np.array(y).reshape(-1,1) X = np.array(X).reshape(-1,1) y = np.array(y) # カテゴリの数値化 from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(["B", "M"]) # 良性:0, 悪性:1 y = le.transform(y.flatten()) # 訓練データ8割、テストデータ2割に分割する from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size = 0.8, test_size = 0.2)
ロジスティック回帰は LogisticRegression クラスを利用して、回帰モデルを作成します。
ロジスティック回帰 (logistic regression) は最もナイーブな機械学習法のひとつである。回帰と称されているが基本的には分類問題に利用される。回帰に使うこともできる.ロジスティック関数、多くの場合,標準ロジスティック関数 (シグモイド関数) の値を学習の過程で計算するが,この値の大小によって分類結果を出力する。つまり、シグモイド関数の出力が0.5より大きい場合を正、それ以外の場合を負、みたいな感じで分類する。中身は単純パーセプトロンと完全に同じもの。(参照:データ科学便覧)
# ロジスティック回帰の回帰モデルを作成する from sklearn.linear_model import LogisticRegression model = LogisticRegression() # 訓練データを回帰モデルに設定する(命令を追記すること) model.fit(X_train, y_train)
テストデータを回帰モデルに当てはめて予測を実施します。
# 予測を実行する y_pred = model.predict(X_test)
予測の精度を混合行列で示してみます。
# 混合行列で集計結果を表示する from sklearn import metrics print(metrics.confusion_matrix(y_test, y_pred))

# 正答率を表示する print(metrics.classification_report(y_test, y_pred))

計測データを91%の確率で判別する事ができました。
ロジスティク回帰のグラフを表示します。
# ロジスティック回帰のグラフを描くために必要な関数と処理。
def logit(x, lr):
return x * lr.coef_ + lr.intercept_
def p(x, lr):
return 1 / (1 + np.exp(-logit(x, lr)))
import math
X_test_min = math.floor(np.min(X_test))
X_test_max = math.ceil(np.max(X_test))
%matplotlib inline
import matplotlib.pyplot as plt
# テストデータを青色の散布図として表示する
plt.scatter(X_test, y_test, color = "blue")
# ロジスティック回帰の曲線グラフを赤色の線で表示する。ここの内容は変更しない!
X_plot = np.arange(X_test_min, X_test_max)
plt.plot(X_plot, p(X_plot, model).flatten(), color = "red")
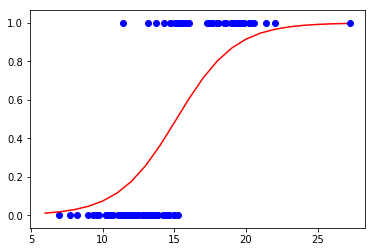
機械学習の結果、9割程度の精度で悪性か良性かの判定を行うことができました。 今回は学習用のテストデータを使った分類でしたが、実際の医療現場においても、医者の見落としを防止するための研究はかなり実用化されており、日々進化しています。
兵庫県立大学では医学部と工学部を併設して医工学という分野で、未来の医療に役立つ研究をしています。 その一つとして「医療ビッグデータの人工知能解析による診断支援システム」があります。
AIの研究をするには質の良いデータが無いと成果は出せないんですね。 やはり。。。






