Kaggleより住宅情報のデータセットを取得して、機械学習を用いて問題解決を行ったフローをまとめました。
このケースのビジネスゴールは、不動産の自動査定システムを通じて物件売却の問い合わせ件数を伸ばす事としています。 要件とて売却希望のお客様が簡単に入力できる項目から判断し、その場で予測価格を答えられるものが必要とされていました。 実際の作業としては機械学習で使えるデータを作成するのに全行程の8割以上の時間を使いました。
<住宅情報データセットの一部>


今回はデータを可視化した部分のみ掲載します。
plt.scatter(y_test, y_pred_on_test, c='blue')
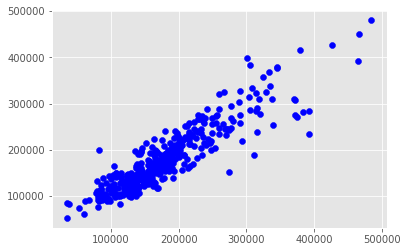
X軸が実際の成約価格で、Y軸が予測した成約価格です。 大きく離れている点については、仮説を立てて検討する必要があるかもしれません。
# 実際の成約価格と予測価格の誤差率をヒストグラムで表示
error_rate = (y_test - y_pred_on_test) / y_test
plt.hist(error_rate)
print('Mean: ', np.mean(error_rate))
print('Std: ', np.std(error_rate))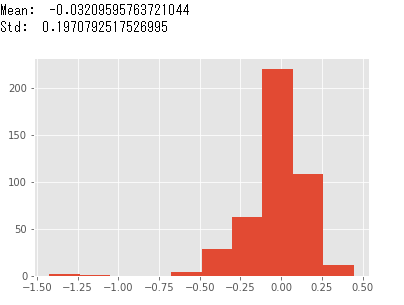
成約価格と予測した成約価格の誤差率をヒストグラムにしてみました。 誤差は少ないと考えますが、50%以上はずれているデータもあるので、お客様の要求レベルによっては再検討が必要かもしれません。
(用語解説)平均二乗誤差(MSE:Mean Square Error)とは 線形回帰モデルの性能を数値化する手法の一つで、実際の値とモデルによる予測値との誤差の平均値です。
![\[\operatorname{MSE}=\frac{1}{n}\sum_{i=1}^n(y_i-\hat{y_i})^2\]](https://labo.akutagawa.com/wp-content/ql-cache/quicklatex.com-403f5a44404179f8e044823d72efa209_l3.png "Rendered by QuickLaTeX.com")
 : 実際値
: 実際値 : 予測値
: 予測値





