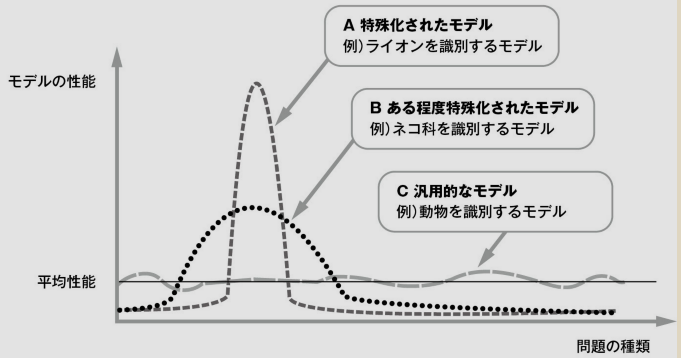
機械学習におけるモデル選定や学習量については、どの問にも高い性能を発揮するモデルは作れません。これをノーフリーランチ定理といいます。この問題にはこのモデルが良いはずだという、その選び方が重要になります。
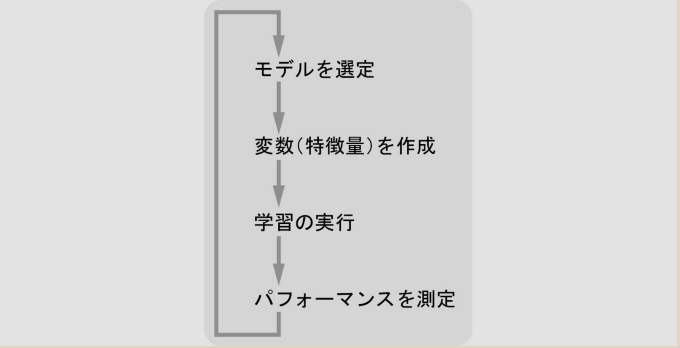
機械学習用に収集した生のデータというのは整理されてないものなので、そのままではモデルのインプットには使えません。これをモデルにインプットできるきれいな形に変換する必要があります。 これは前処理とか特徴量変換と呼ばれる過程となります。
堅田洋資; 菊田遥平; 谷田和章; 森本哲也. フリーライブラリで学ぶ機械学習入門 (参照)
まず機械学習させるデータを精査する前処理が必要になります。 この作業が全体の8割を占めるとされています。 またデータの特徴量を決めるには、センスと知識が要求されます。 また、機械学習で使うアルゴリズム(モデル)の選定も、何が最適かを使う人が判断しなければなりません。 この段階では統計学や数学的な知識が欠かせないようです。
- 欠損値を補完した場合の論理的な説明が必要
- 特徴量の設計に関しては、想像力を豊かにする
- 住宅の場合、間取りと駅から距離などから、分析に使えると仮説をして新しい特徴量を作るなど